כאשר אנו כותבים תוכנית C# לרוב לא יהיה לנו צורך בניהול זיכרון ידני, שכן ל-Microsoft .NET יש "אוסף זבל" – (Garbage Collector) אשר אחראי להשליך לפח אובייקטים אשר סיימנו להשתמש בהם, אך למרות זאת, יש לנו צורך להבין מה זה Stack & Heap וכיצד מתבצע ניהול הזיכרון מאחורי הקלעים על מנת שנוכל לכתוב תכניות יעילות יותר אשר צורכות פחות משאבי זיכרון.
הבנה בסיסית של כיצד מתבצע ניהול הזיכרון האוטומטי על ידי Microsoft .NET תעזור לנו להבין כיצד מתנהלים המשתנים שלנו מבחינת זיכרון בכל תוכנית שנכתוב.
ב- Microsoft .NET קיימים שני מקומות שבהם אחסון הזיכרון מתבצע שהם ה-Stack & Heap.
ניתן להסתכל על כל אחד מהם כעל שיטת אחסון שונה שהמערכת משתמשת בה על מנת לשמור את המשתנים שלנו במיקומי זיכרון שונים.
מיד נבין את ההבדלים ואת תפקידו של כל אחד מהם.
Heap & Stack – ההבדלים
Stack
ניתן לומר כי ה-Stack היא מעין מחסנית אשר מאכסנת בתוכה קופסאות אשר מסודרות אחת על גבי השנייה, כאשר מה שנכנס אחרון – יוצא ראשון (LIFO).
ניתן לומר מה שמאוחסן בתוך הקופסאות שבמחסנית זה מעין תיעוד של כל מה שרץ בתוכנית, או כל מה שאנחנו "קוראים לו".
כלומר שהמתודה האחרונה שנטענה ל-Stack היא הראשונה שה-Garbage Collector ינקה מהזיכרון.
בתוך ה-Stack יש לנו גישה רק לפריט האחרון שנכנס למחסנית, עד שהוא ינוקה מהזיכרון, ואז הפריט הקודם בתור יהיה בראש המחסנית.
Heap
אופן הפעולה של ה-Heap שונה מזה של ה-Stack.
את ה-Heap נוכל לתאר כתפזורת של פריטים בתוך קופסא, כאשר ניתן לגשת לכל אחד מהם בלי קשר למתי הוא נכנס.
בניגוד ל-Stack כאן כן נצטרך להתחשב בניהול זיכרון, שכן ניתן לגשת לכל אחד מהפריטים שבו בלי תור.
מה נכנס ולאן?(!)
כאשר אנו מדברים על Stack & Heap יש ארבעה משפחות טיפוסים (טייפים) עיקריים שאנו עובדים איתן:
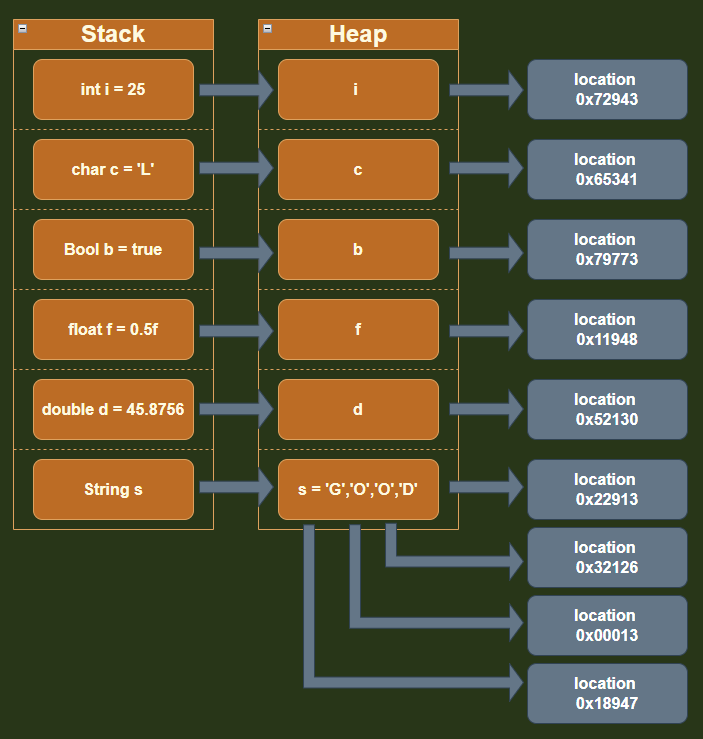
Value Types
בשפת C# הטיפוסים הבאים נחשבים כ- Value Type ויאוכסנו היכן שהם הוגדרו:
- bool
- byte
- char
- decimal
- double
- enum
- float
- int
- long
- sbyte
- short
- struct
- uint
- ulong
- ushort
Reference Types
בשפת C# הטיפוסים הבאים נחשבים כ- Reference Type ויאוכסנו תמיד ב-Heap:
- class
- interface
- delegate
- object
- string
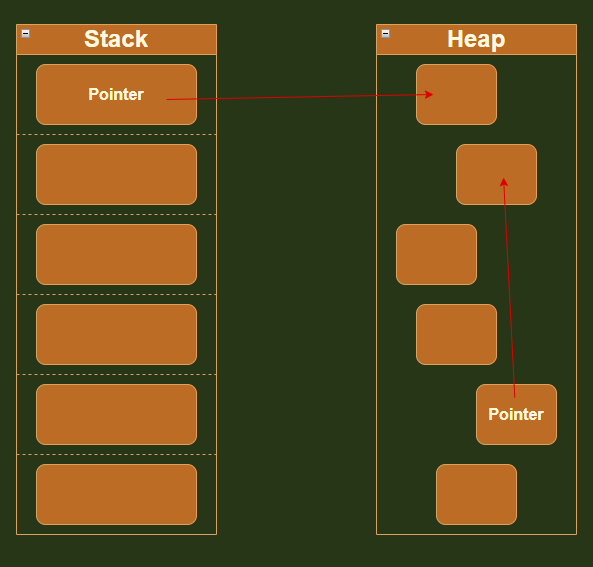
Pointers
הסוג השלישי שאנו יכולים לאכסן בזיכרון הוא פוינטר, כלומר מצביע לכתובת זיכרון ספציפית שהערך שהוא מכיל יכול להיות גם null.
בשפת C# אין לנו צורך להשתמש במצביעים באופן מפורש, שכן זוהי עבודה אשר מתבצעת באופן אוטומטי על ידי ה- CLR.
טיב היחסים בין מצביע לבין Reference Type הוא כזה שאנו משתמשים במצביע על מנת לגשת אל המיקום בזיכרון של משהו שהוגדר כ-Reference Type.
הפוינטר עצמו יכול להיות ממוקם למשל ב-Stack ומשם הוא מצביע למקום האכסון ב-Heap,
נראה גם מצבים שבו המצביע ממוקם ב-Heap ומצביע למקום האכסון גם ב-Heap, ועוד.
Instructions
אלו הן למעשה ההוראות שניתנות לקומפיילר כיצד עליו להריץ את התוכנית ומאוכסנות ב-Stack לפי שיטת ה-LIFO שעליה דיברנו מקודם.
כאשר ה-Stack מתרוקן התוכנית למעשה מגיעה לסיומה.
אז איך זה עובד
כפי שהוסבר, כל מה שמוגדר כ-Reference Type, יאוכסן ב-Heap,
לגבי Value Type – ובכן זה קצת יותר מורכב, הם מאוכסנים במקום שבו נוצרו, התבוננו בתרשים הזרימה הבא ומיד נבאר את הנושא.
שימו לב לדוגמא הבאה:
public int MultiplyTen(int myValue)
{
int myResult;
myResult *= 10;
return myResult;
}
כפי שניתן לראות מתודה זו תקבל ערך מספרי שלם כפרמטר ותכפיל אותו פי 10.
כאשר תתחיל המתודה היא תיצור את המשתנה – myResult בסטאק ותשמור לו מקום בזיכרון,
המתודה אמורה להסתיים כך ש-myResult יקבל ערך ויונח בראש ה-Stack,
כלומר שברגע שאוסף הזבל ינקה את myResult מהזיכרון, תימחק גם המתודה והערך המספרי ששלחנו לה כפרמטר.
לעומת זאת, ValueType שניצור בתוך Reference Type יאוכסן ב-Heap בתוך אותו ה-Reference Type.
נניח שיש ברשותנו מחלקה בשם – MyNumber אשר מכילה את הערך המספרי:
public class MyInt
{
public int myValue;
}
והמתודה שכתבנו נראית כך:
public MyInt MultiplyTen(int myValue)
{
MyInt result = new MyInt();
result.myValue *= 10;
return result;
}
מה שיקרה עכשיו זה שמהסיבה ש-MyInt הוא Reference Type, ב-Stack יאוכסן פוינטר אשר מצביע לכתובת הזיכרון ב-Heap.
לאחר שהמתודה תסיים את פעולתה והאוסף זבל ינקה את הערימה שהיא יצרה מה-Stack,
נישאר רק עם מה שאוכסן ב-Heap, כל המתודה כולל המצביע שהיא יצרה ימחקו מה-Stack.
כעת הכול יאורגן מחדש ב-Heap, משהו שעלול להיות לו מחיר של כוח עיבוד וכדומה, ולכן עלינו להבין איך זה עובד.
שימו לב לדוגמא הבאה, בהקשר של אותה המחלקה שיצרנו מקודם:
public int ReturnNumber()
{
int num1 = 7;
int num2 = num1 ;
y = 2;
return num1;
}
כאשר נריץ את התוכנית נקבל את התוצאה – 7 כמובן, משום ש-num1 הוא Value Type,
ולמרות שהזנו אותו למשתנה num2, הערכים של שני המשתנים אינם קשורים By Refernce, ואם שנשנה את הערך של num2 לא נשפיע על num1.
אך אם נשתמש במחלקה שיצרנו על מנת לכתוב את המתודה:
2public int ReturnNumber()
{
MyInt num1 = new MyInt();
num1.myValue = 7;
MyInt num2 = new MyInt();
num2 = num1;
num2 .myValue = 2;
return num1.myValue ;
}
כעת התוצאה שנקבל תהיה 2.
כאשר אנו מזינים את num1 לתוך num2, מאותו הרגע שניהם חולקים מיקום זיכרון משותף.
הפוינטרים של num1 ו-num2 ימוקמו ב-Stack, עד לאותו הרגע שהמתודה תסיים את פעולתה ותתנקה מהזיכרון עם הפוינטרים.
סיכום
לסיכום ניתן לומר כי ללא הבנה של מה מתחולל מאחורי הקלעים כאשר אנו מכריזים על משתנים ובונים מחלקות – אנו עלולים למצוא את עצמנו במצבים של ביזבוז משאבים.
כמובן שניתן להיכנס לעומק ולהרחיב עוד על הנושא, אך הבנה טובה של הנושא מאפשרת לנו לכתוב תוכניות יעילות ואף חשובה.
קידוד מהנה.